SSRL
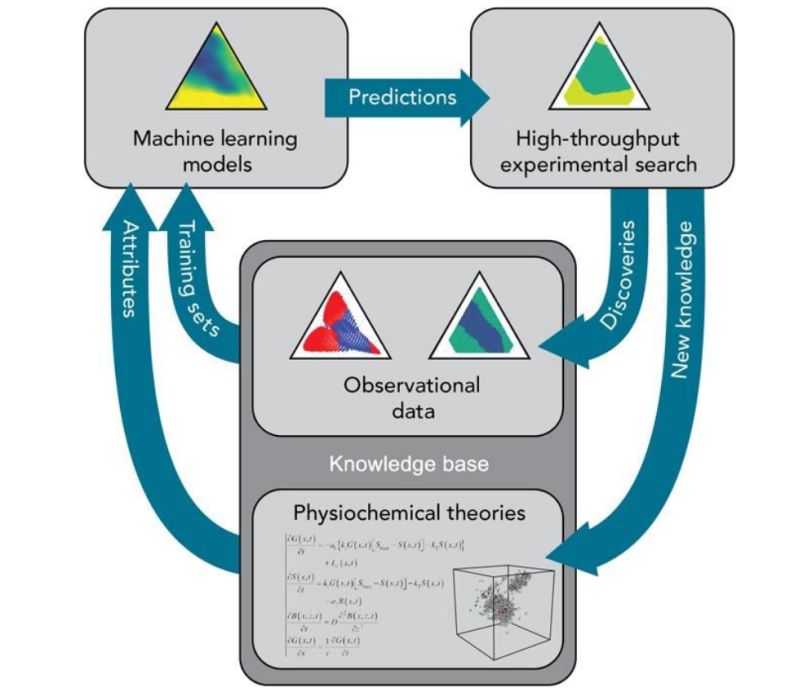
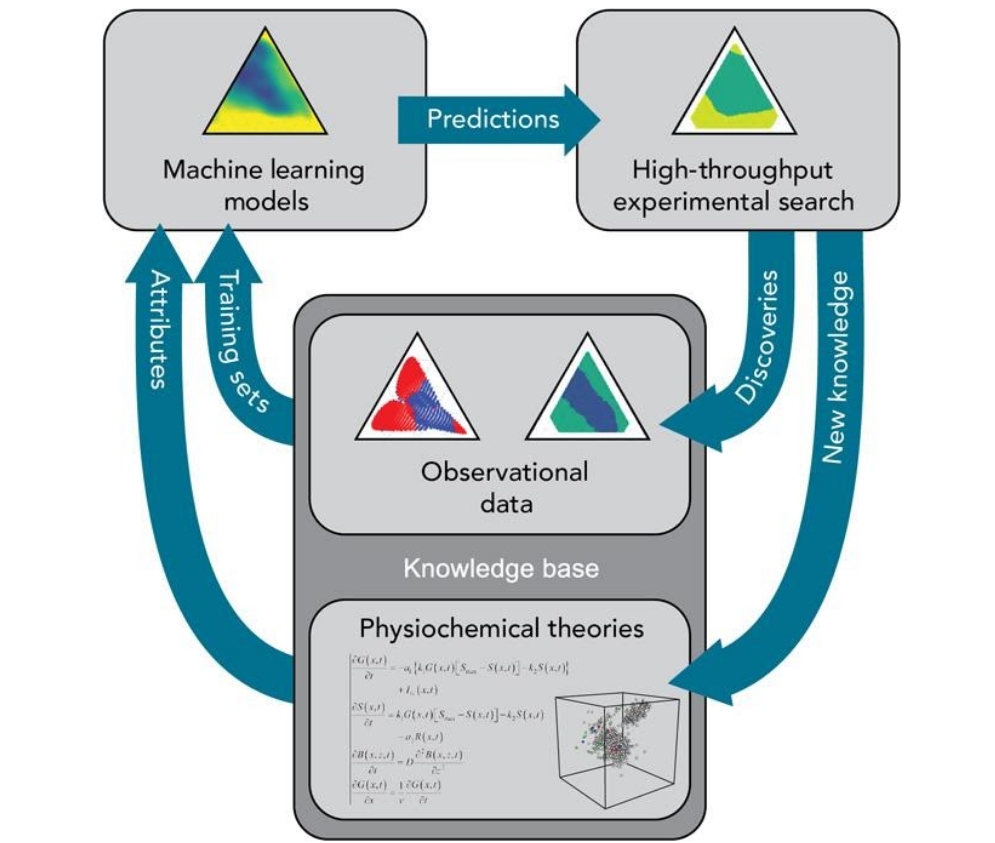
Every year, Stanford Synchrotron Radiation Lightsource (SSRL) supplies high intensity x-rays to [thousands] of scientists from a variety of disciplines tackling diverse problems. Although the experimental needs of each scientist vary, all users of SSRL are united by the need to transform data into scientific knowledge and insight. Often, this process is the bottleneck for our users. As brighter light sources enable data to be collected at increasingly fast rates, processing data will become an increasingly daunting problem. At SSRL we are using ML to expedite this process, helping users gain high-level insights on-the-fly.
The variety of problems being tackled at SSRL provides a unique challenge, requiring solutions to be robust and generalizable. In particular, we are adapting unsupervised machine learning techniques to problems in x-ray characterization, facilitating insights regardless of the material being examined. Applications include high level data aggregation for automatic phase identification (clustering and segmentation), as well as intelligent data acquisition (active search, gaussian processes).
High Level Data Aggregation
we are adapting unsupervised machine learning techniques to problems in x-ray characterization, facilitating insights regardless of the material being examined. Applications include high level data aggregation for automatic phase identification (clustering and segmentation), as well as intelligent data acquisition (active search, gaussian processes).
{kind=link}
Exploration of new wear resistant metallic glasses has been stymied by sheer number of possible alloy compositions. We have used machine learning in conjunction with high throughput data collection methods to guide our search for metallic glasses, allowing us to traverse this vast sample space quickly and efficiently. Automated peak detection and analysis extracts features from diffraction images, which are used as training data for a random forest classification model.
ML Workflow
We have used machine learning in conjunction with high throughput data collection methods to guide our search for metallic glasses, allowing us to traverse this vast sample space quickly and efficiently. Automated peak detection and analysis extracts features from diffraction images, which are used as training data for a random forest classification model.
{kind=link}
Raster scanning a probe beam across a sample pixel-by-pixel is a common approach to measurements at light sources. Beams can be scanned spatially (for example in X-ray fluorescence imaging), in spectrum (for example in resonant inelastic x-ray scattering) or in time (for example in pump-probe dynamics experiments). As the number of dimensions or number of pixels grows, raster scanning quickly becomes unfeasible, lowering the achievable resolution. For sparse samples, the raster approach can be suboptimal. For example, in particle detection, a large fraction of the pixels may encode no information. Instead, by adaptively changing the resolution during the scan, it is possible to focus the costly high-resolution measurements on only the highest value portions of the sample. As a first demonstration, we are using a reinforcement learning (RL) approach to improve X-ray fluorescence scanning; the RL agent treats the data acquisition process as a game, with the goal of maximizing information in the shortest amount of time. An early result, simulated on an existing data set, is shown below:
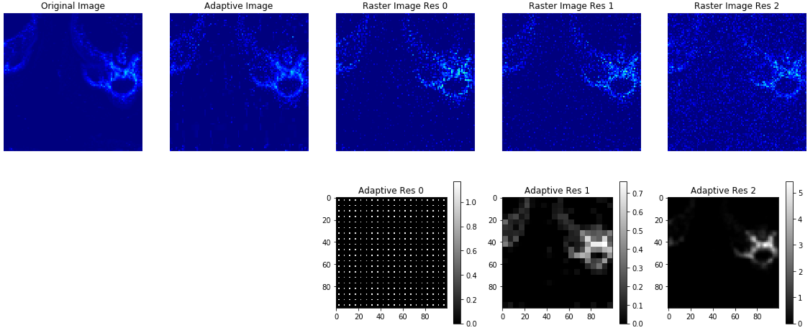
X-ray fluorescence scanning
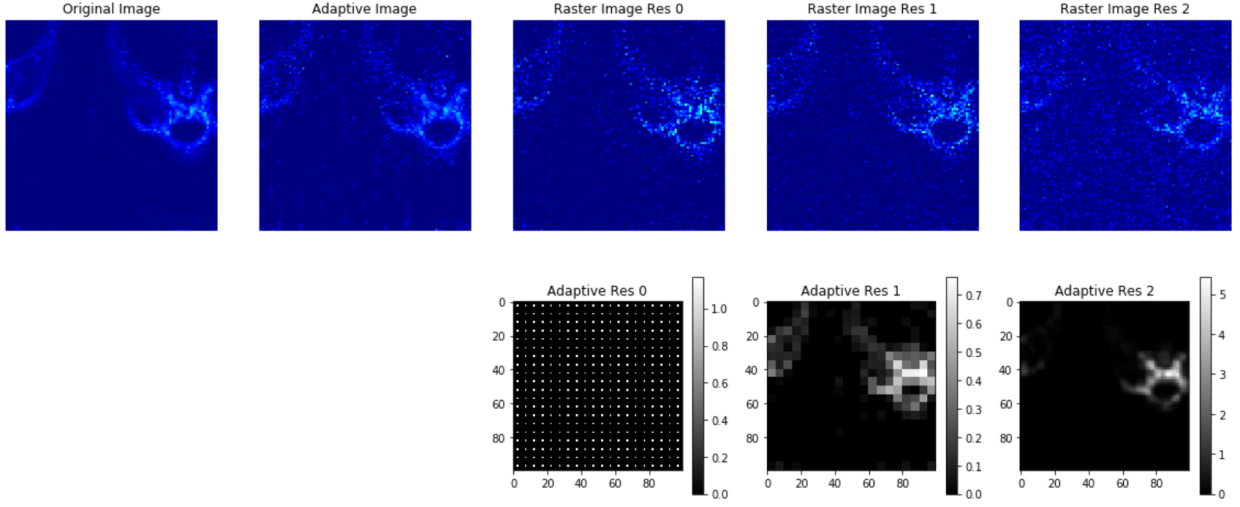
Top row far left shows an XRF scan. Second from left shows an adaptive resampling, with an RL algorithm deciding the duration and resolution for each measurement. The rest of the row shows the current measurement approach of using a raster scan of either low, medium, or high resolution, yielding noisier or lower resolution reconstructions. Below, second row shows the durations chosen by the RL algorithm. The RL algorithm starts with a raster-like scan at low resolution (left most plot), before identifying interesting regions for higher-resolution scans (middle and right plots).
{kind=link}